为什么是插件,而不是 Python
先说结论:Python 当然能采,而且在批处理、离线计算、定时任务、接口调用这些事情上依然非常强。但如果你的目标是“采一个我正在浏览的网站”,尤其这个网站还牵涉账号登录、页面滚动、懒加载、动态渲染、按钮点击、二次弹窗、前端加密参数这些细节,那么浏览器插件天然就站在离目标更近的位置。
插件运行在浏览器环境里,直接复用当前用户已经登录的状态。你打开网页、搜索关键词、切换排序、下滑列表、点开详情,这些动作本来就是你每天在做的真实操作。插件做的事情,不是绕到外面重新模拟一个世界,而是在你已经打开的世界里,把你眼前看到的数据结构化地拿出来。
这也是我越来越喜欢插件方案的核心原因:它不是更“高级”,而是更“贴身”。很多时候,业务真正需要的不是一个理论上无所不能的爬虫系统,而是一个能跟着当前工作页面走、十分钟内就开始出结果的数据助手。
插件采集的几个现实优势
账号与登录状态
插件直接使用浏览器里的登录态,不需要你另外处理 Cookie 持久化、扫码登录续期、风控验证这些额外成本。很多平台最难的不是请求本身,而是“稳定地保持在已登录状态”。插件在这件事上占天然优势。
所见即所得
网页上能看见的数据,大概率就能采。你只要能在页面上定位到标题、作者、点赞、评论、标签、发布时间、详情文案,就能围绕这些元素做提取。可视化界面降低了试错成本,定位起来比黑盒接口轻松得多。
更像真实用户
滚动、点击、展开、切换 Tab、分页,这些都是浏览器的原生行为。插件在真实页面内完成这些动作,路径更自然,也更容易处理前端框架产生的动态内容。
更适合让 AI 帮你开发
你只要把页面结构、元素选择器、采集目标、导出字段告诉 AI,它就能帮你把插件逻辑快速搭起来。你不一定要先精通整个浏览器扩展体系,也能先做出一个能跑的版本。
“看得见的数据都能采”这句话,为什么成立
很多人把网页采集想得过于神秘,实际上第一步往往并不复杂:打开开发者工具,观察页面里对应内容的 DOM 结构,找到稳定的元素特征,然后把这些信息发给 AI。比如你告诉它:
- 列表项外层容器是哪一个
- 标题、作者、点赞数、评论数分别在哪个节点里
- 点击列表后详情页的正文位于哪里
- 页面向下滚动时新内容是如何加载的
- 导出时需要哪些字段
一旦这些信息明确,剩下的工作就从“我想做个采集器”这种模糊愿望,变成了一连串可执行的前端自动化动作。AI 在这里最擅长的不是替你凭空猜需求,而是把已经说清楚的页面规则转成代码。
开发插件时,最重要的不是灵感,而是拆目标
我经常看到一种提需求方式:“我想要一个爆款生成视频的软件。”这句话的问题不是野心大,而是没有信息密度。AI 没法替你补完所有决定,开发也无法直接开工。
更有效的方式,是先总后分。先有一个总目标,再把它拆成一个个具体目标。比如如果你要做某书采集器,真实的需求拆法应该更像这样:
当需求被拆到这个颗粒度,AI 能写代码,人能验收结果,产品也能迭代。你会发现,真正决定开发速度的,不是你会不会编程,而是你会不会把目标说清楚。
采集完成后,数据怎么用,比采集本身更重要
很多人做采集,停在“拿到了数据”这一步。其实真正拉开差距的,是后面的数据流转与分析方式。采集器如果只是把一堆内容堆在本地表格里,价值只释放了一半。更值得考虑的是,数据下一站去哪儿,以及你想从里面得到什么。
保存本地
适合做归档、备份、简单筛选和二次清洗。CSV、Excel、JSON 都是常见起点。
发送到在线文档
适合团队协作。比如推送到飞书多维表、在线表格,让运营、内容、销售同时接手处理。
接 AI 分析
适合从海量文本里找规律,比如爆款结构、用户痛点、关键词聚类、选题方向和竞品差异。
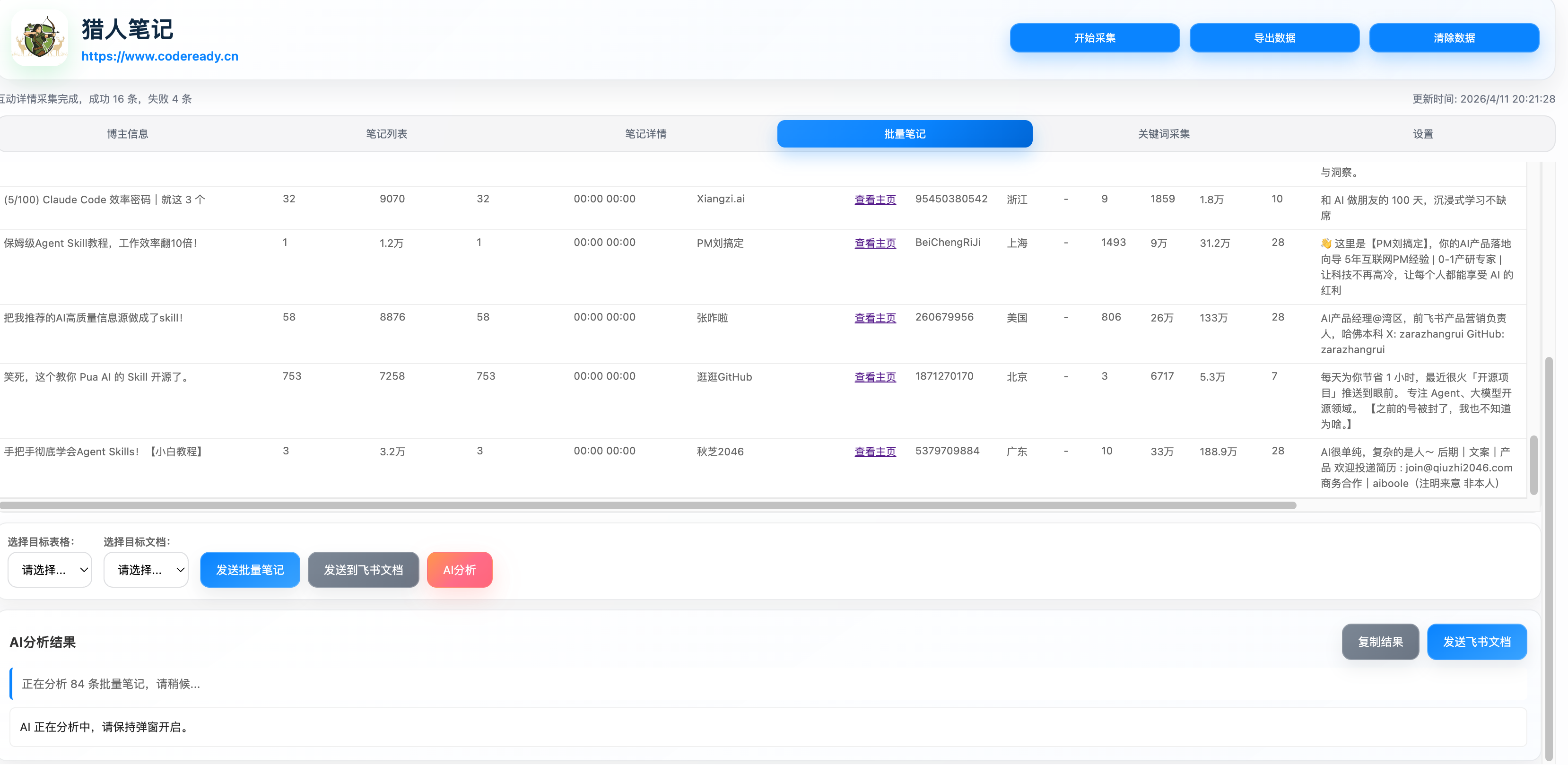
所以一个成熟的采集插件,最好别只解决“采”,还要考虑“存”“传”“析”。这也是为什么像截图中的猎人笔记这类工具,会把批量笔记、在线文档和 AI 分析放到同一条流程里。真正好用的工具,不是一个按钮,而是一条完整工作流。
DeepSeek 还是 ChatGPT,关键不在模型名,而在你要什么结果
这类问题最容易被讨论偏。模型选择当然重要,但在很多实际场景里,真正决定结果质量的,是你的输入数据是否干净、目标是否明确、提示词是否写到了可执行层。
如果你采回的是几十条到几百条某书笔记内容,常见的 AI 分析目标通常有四类:
- 找高频主题,看看大家都在聊什么
- 总结爆款结构,拆标题、开头、情绪点、转化点
- 挖用户痛点和具体需求
- 输出下一步动作,例如选题清单、内容框架、产品建议
如果你要的是中文场景下的快速归纳、成本可控、批量测试,DeepSeek 可以很好用;如果你更看重复杂推理、长文本整合、稳定的多轮协作,ChatGPT 往往更顺手。选谁不是口号问题,而是你准备用它干什么。
一份更靠谱的 AI 分析提示词,应该怎么写
提示词不要只写“帮我分析这些数据”,那样太空。更好的写法,是把角色、数据、任务、输出格式都限定清楚。下面这个模板,稍微改一下就能直接用:
你现在是一名内容策略分析师。
我会给你一批从某书平台采集回来的笔记数据,字段包括:标题、作者、点赞数、收藏数、评论数、发布时间、正文摘要、标签。
请你完成以下任务:
1. 总结这批内容的 5 个高频主题。
2. 提炼高互动笔记的共同结构,包括标题写法、开头方式、情绪钩子、转化动作。
3. 归纳用户最常出现的 10 个痛点或需求。
4. 输出 20 个值得继续创作的新选题。
5. 用表格给出结果,列包含:主题、证据、洞察、可执行建议。
要求:
- 结论必须引用我给的数据特征,不要空泛发挥。
- 优先输出可执行建议,而不是大而空的总结。
- 如果数据不足,请明确指出缺口,并告诉我还应该补采什么字段。这类提示词的关键,不是写得华丽,而是让 AI 明白你到底要交付什么结果。你最后要的是文章选题、客户洞察、竞品总结,还是销售线索,不同目标对应的提示词结构完全不同。
最后想说
插件采集不是为了替代所有方案,而是为了解决一类特别现实的问题:我已经在网页里,我已经登录了,我已经看到这些内容了,我想把它们快速、稳定、低门槛地拿出来,并立刻进入下一步处理。
从这个角度看,某书采集器、关键词采集器、表格填充插件、飞书同步工具、AI 分析助手,本质上都不是孤立的软件,而是围绕“网页数据工作流”搭起来的一组能力。
如果你也想开发插件,不妨先别问“能不能做一个很厉害的软件”,而是先问自己三件事:我要采什么,我要怎么采,我采完之后准备拿它干什么。把这三件事想明白,AI 才能真正帮你把工具做出来。